JavaScript
关于JavaScript
JavaScript(JS)是单线程的、基于原型的、弱类型的、动态类型的、轻量的、支持面向对象/命令式/声明式编程的、头等函数的、多范式的、解释性(直译式或即时编译)的、也可在非浏览器环境下使用的动态脚本语言。JavaScript区分大小写。JavaScript 中,通过在运行时给空对象附加方法和属性来创建对象并且可以作为创建相似对象的原型。
浏览器JavaScript由三部分组成:核心ECMAScript 描述了该语言的语法和基本对象;DOM 描述了处理网页内容的方法和接口;BOM 描述了与浏览器进行交互的方法和接口。
JavaScript 的动态特性包括运行时构造对象、可变参数列表、函数变量、动态脚本执行(通过 eval)、对象内枚举(通过 for ... in)和源码恢复(JavaScript 程序可以将函数反编译回源代码)。
JavaScript® 是 Oracle 在美国和其他国家的商标或注册商标。
编译原理与编译过程
在代码执行之前会经历词法分析、语法分析和代码生成的编译阶段。
- 词法分析(Lexing)会将由字符组成的字符串分解成有意义的代码块即词法单元(Token)。
- 语法分析(Parsing)是将词法单元流转换成一个由元素逐级嵌套所组成的代表了程序语法结构的树即抽象语法树(AST,Abstract Syntax Tree)。
- 代码生成是将 AST 转换为可执行代码。
V8 的执行过程:
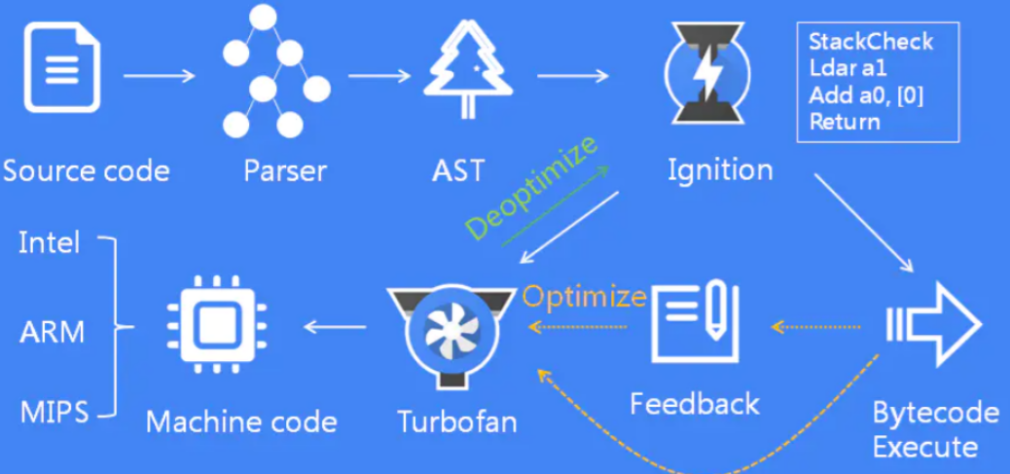
源代码经过 Parser 解析器,经过词法分析和语法分析生成 AST;AST经过 Ignition 解释器生成字节码并执行;在执行过程中,如果发现热点代码,将热点代码交给 TurboFan 编译器生成机器码并执行;如果热点代码不再满足要求,进行去优化处理即还原成字节码并把执行权交还给 Ignition 解释器。
执行上下文和作用域
JavaScript代码是运行在执行上下文中的,创建新执行上下文的方式有:
- 全局执行上下文:为函数之外的任何代码创建的上下文。
- 函数执行上下文:每个函数执行时创建的上下文。创建个数没有限制。
- eval执行上下文:eval函数执行创建的上下文,不建议使用可忽略。
每一个上下文在本质上都是一种作用域层级,每个上下文创建的时候会被推入执行上下文栈(Execution Context Stack,或者叫函数调用栈(Call Stack)),栈顶是当前执行的上下文,执行完代码退出的时候从上下文栈中移除,栈底是全局执行上下文。(注意:JavaScript 中,以回调方式调用的函数,是否会形成类似于递归那样“一层套一层” 的调用链而存在堆栈溢出的风险,取决于父函数执行完毕之前是否再次调用 “父” 函数,比如 setTimeout、nextTick、promise.then/catch/finally、MutationObserver等是在任务队列中执行,再次调用“父”函数时,父函数已经执行完毕,即不存在堆栈溢出的危险)。
function fun2() {
console.log('fun2');
}
function fun1() {
fun2();
}
fun1();
/**
模拟:
// fun1()
ECStack.push(<fun1> functionContext);
// fun1 中调用了 fun2, 所以还要创建 fun2 的执行上下文
ECStack.push(<fun2> functionContext);
// fun2 执行(创建作用域链 => 变量对象 => 执行代码)完毕
ECStack.pop();
// fun1 执行(创建作用域链 => 变量对象 => 执行代码)完毕
ECStack.pop();
*/变量对象(Variable object,VO)是与执行上下文相关的数据作用域,存储了在上下文中定义的变量和函数声明。作用域即执行上下文,由多个作用域的变量对象构成的链表就叫做作用域链。函数创建时,每个函数的[[Scopes]]属性在会保存所有父级作用域内的变量对象。
全局对象的通用变量名是通用名称 globalThis,特定环境名称分别是:
- 浏览器——window;
- Worker——WorkGlobalScope;
- nodejs——global;
全局变量提供可在任何地方使用的变量和函数。默认情况下,这些全局变量内建于语言或环境中。
执行上下文中的代码会分成两个阶段进行处理:
进入执行上下文:
- 如果是函数执行上下文,会复制函数
[[scope]]属性到函数执行上下文的 Scopes 属性来初始化作用域链。 - 然后创建变量对象:全局执行上下文的变量对象初始化是全局对象。函数执行上下文的变量对象初始化是只包含 Arguments 对象的对象。如果是函数执行上下文则首先给当前执行上下文的变量对象添加形参及初始值,否则先添加函数声明(函数表达式属于后面的变量声明)及初始值,再添加变量声明(带声明var/let/const关键字的)及初始值,完成后被激活为活动对象(Activation Object,AO);因此,变量提升(Hosting)是JavaScript执行上下文工作方式,意味着变量和函数的声明在编译阶段即执行阶段之前被放入内存中,就好像声明处在作用域最前面。由执行上下文的两个处理阶段可知,函数声明提升(非函数表达式)优先于变量声明提升(var、let、const);
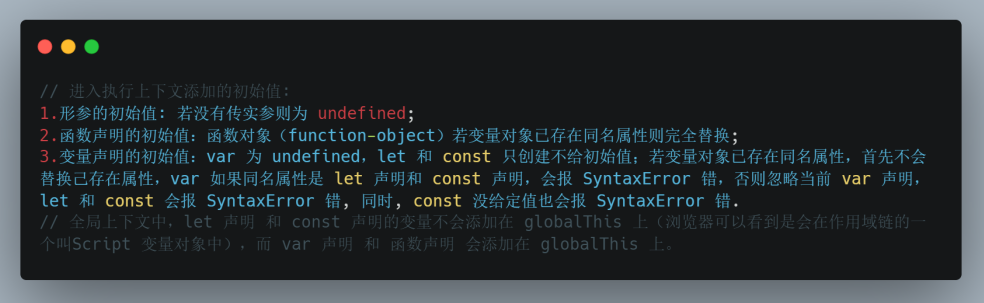
- 如果是函数执行上下文,会将活动对象压入函数执行上下文的Scopes属性即作用域链顶端。
javascriptfunction foo() { function bar() { // do something } } // foo 函数创建时 foo.[[Scopes]] = [ globalContext.VO ]; bar.[[Scopes]] = [ fooContext.AO, globalContext.VO ]; // bar 函数执行上下文 barContext = { AO: { arguments: [] }, Scope: [AO, fooContext.AO, globalContext.VO], this: undefined }- 如果是函数执行上下文,会复制函数
代码执行:
- 访问并修改活动对象的属性值。对于let 或 const 声明的变量,从一个代码块的开始直到代码执行到声明变量的行之前,变量都处于“暂时性死区”(Temporal dead zone,TDZ),尝试访问即使是typeof也将抛出 ReferenceError;只有当代码执行到声明变量所在的行时,才会对其进行初始化(若未赋值,则初始化为 undefined)。
- 执行完后将函数执行上下文从执行上下文栈中弹出。
作用域即执行上下文,由多个作用域的变量对象构成的链表就叫做作用域链。函数在执行前会复制该函数 [[Scopes]] 属性到函数执行上下文中创建作用域链。当访问一个变量时,解释器会首先在当前作用域的变量对象中查找标识符,如果没有找到,就去父作用域找,直到找到标识符,如果全局作用域也找不到就报错。因此,一个变量或函数在整个作用域链都没有声明,那么在代码执行阶段就会报 ReferenceError 错。
作用域共有两种主要的工作模式:词法作用域(静态作用域)和动态作用域。JavaScript 采用词法作用域(Lexical Scope)。词法作用域根据源代码中声明变量的位置来确定该变量在何处可用,而动态作用域 并不关心函数和作用域是如何声明以及在何处声明,它只关心它们从何处调用。
const a = 2;
function foo() {
console.log(a);
}
function bar() {
const a = 3;
foo();
}
bar();
// JS 是词法作用域,所以输出 2
// 假如是动态作用域则输出 3JavaScript的词法作用域分为:
- 全局作用域:脚本模式运行所有代码的默认作用域。
- 模块作用域: 模块模式中运行代码的作用域。 Node 中顶级作用域不是全局作用域,而是当前模块作用域。
- 函数作用域:由函数创建的作用域。函数作用域指属于这个函数的全部变量都可以在整个函数的范围内访问。 使用 let(ES6)、const(ES6)声明的变量和Function 构造函数声明的函数属于额外的块级作用域(被限制在定义它的代码块内——块由一对大括号界定)。
this
this是执行上下文的一个属性,在非严格模式下指向一个对象,严格模式下可以是任意值。
在全局上下文(任何函数体外部)中,无论是否为严格模式,this指向全局对象。
在函数上下文中,this的值取决于函数被调用的方式(运行时绑定,箭头函数除外),函数的调用方式包括:
- 方法调用模式即作为对象的属性被调用;
- 普通调用模式即普通的函数调用;
- 构造函数调用模式即使用 new;
- 间接调用模式即 call、apply 调用;
默认情况即普通函数调用模式下,非严格模式中 this 指向globalThis,严格模式中指向undefined,因此this可以用来判断当前是否处于严格模式:
javascriptfunction isStrict() { return this === void 0; }在类(class,ES6)上下文中,类中所有非静态的方法都会被添加到 this 的原型中。子类的构造函数中没有初始的this绑定,需要调用super()才会生成this绑定,因此在调用super()之前访问this会报错。而且子类不能在调用 super() 之前创建实例返回,除非其构造函数返回的是一个对象,或者根本没有构造函数。类内部总是严格模式,调用一个 this 值为 undefined 的方法会抛出错误。
nodejs环境下的模块中,this指向module.exports。而浏览器环境下的模块中,顶级 this 是 undefined。
当函数作为对象里的方法(包括getter、setter、原型链上的方法)、DOM事件处理函数、内联事件处理函数调用时,this 被设置为调用该函数的对象和元素。
显示绑定函数的this方式:bind,call,apply,对箭头函数来说不能绑定 this即第一个参数会被忽略,只能传递参数。在非严格模式下使用 call 和 apply 更改函数的 this 绑定时,如果用作 this 的值不是对象,则会被尝试转换为对象:
- null 和 undefined 被转换为全局对象;
- 其他原始值会使用对应的构造函数转换为对象,比如 7 会被转换为 new Number(7),'foo'会被转换为 new String('foo');
- bind 函数会创建返回与原函数具有相同函数体和作用域的函数,新函数的 this 将被永久地绑定到首次 bind 的第一个参数,后续无论如何调用或更改绑定,this 不会变。
箭头函数不会创建自己的this,它只会从自己的作用域链的上一层继承 this,即箭头函数保持为创建时封闭词法作用域的this值(箭头函数不是封闭词法作用域)。关于“ this”的严格模式区别规则在箭头函数中将被忽略。针对箭头函数判定this的简便方法:在箭头函数创建的位置将整个箭头函数替换为this,则箭头函数的this就是这个被替换的this,如果有多层箭头函数,则重复这个步骤。
Proxy 代理对象调用方法时,原对象内部的 this 指向其代理对象。handler 拦截函数内部的 this,指向的是 handler 对象本身。
对象方法的链式调用通过该方法返回当前对象实现。
内存管理与垃圾回收
内存管理
编程语言的内存生命周期均包括三部分:
- 分配所需要的内存,JavaScript中发生在值的初始化和函数调用返回。
- 使用分配到的内存(读、写)
- 不需要时将其释放\归还,即垃圾回收(Garbage collection,GC),是计算机编程中用于描述查找和删除那些不再被其他对象引用的对象处理过程。
JavaScript 的内存管理是自动的、无形的。在内存管理的环境中,一个对象如果有访问另一个对象的权限(隐式或者显式),叫做一个对象引用另一个对象,“对象”的概念包括 JavaScript 对象和函数作用域(或者全局作用域)。特别注意,全局变量的生命周期直到浏览器卸载页面才会结束,也就是全局变量不会被当成垃圾变量回收。
垃圾回收
引用计数法
最初级的引用计数法:将“对象是否不再需要”简化定义为“对象有没有其他对象引用到它”,因此如果没有引用指向该对象(零引用),对象将被垃圾回收机制回收。该方法存在循环引用的内存无法被回收的问题。
标记清除法
标记清除法:将“对象是否不再需要”简化定义为“对象是否可达”。假定设置一个设置一个叫做根(root)的对象(在 Javascript 里,根是全局对象),如果一个值可以通过引用链从根访问,则认为该值是可达的。它相比引用计数法更好,因为“有零引用的对象”总是不可达,即使是循环引用。标记清楚算法缺陷是无法从根对象查询到的对象都将被清除。
function marry(man, woman) {
woman.husband = man;
man.wife = woman;
return {
father: man,
mother: woman
}
}
// 1. 创建引用
let family = marry({
name: 'John'
}, {
name: 'Ann'
});
// 2. 移除两个引用
delete family.father;
delete family.mother.husband;
// 3. 移除外部引用
let family = null;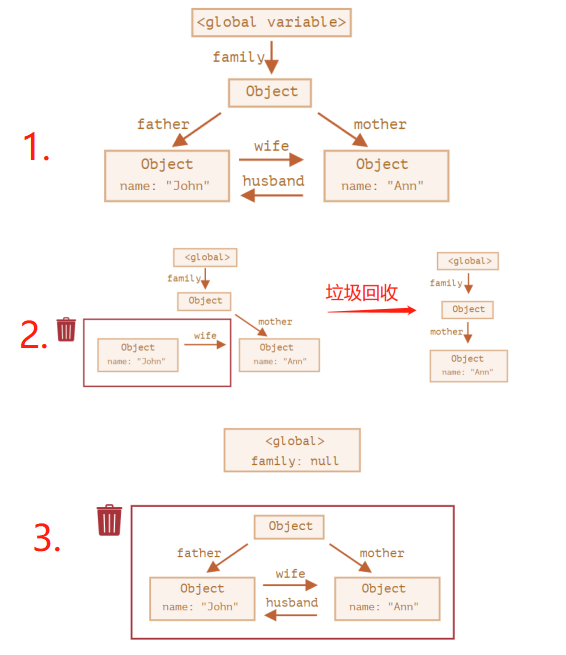

栈内存,ESP 指针下移(即上下文切换),栈顶的空间会自动被回收。
垃圾收集器进行分代收集(Generational collection)(按新生代和老生代收集)、增量收集(Incremental collection)(分多次收集)、闲时收集(在 CPU 空闲的时候)。
堆内存,分为新生代内存(临时分配的内存,存活时间短)和老生代内存(常驻内存,存活时间长)。

新生代的内存在 64 位和 32 位系统下默认限制分别为 32MB 和 16MB(存活时间短,操作更频繁,所以设置小)。
V8 引擎会限制内存的使用(64 位最多只能分配 1.4GB,32 位最多只能分配 0.7GB),因为垃圾回收是非常耗时的操作,同时,回收过程会阻塞线程。以 1.5GB 的垃圾回收为例,V8 做一次小的垃圾回收需要 50ms 以上,做一次非增量式的垃圾回收甚至要 1s 以上。 手动调整老生代:node --max-old-space-size=2048 xxx.js; 手动调整新生代(一般不建议):node --max-new-space-size=2048 xxx.js。
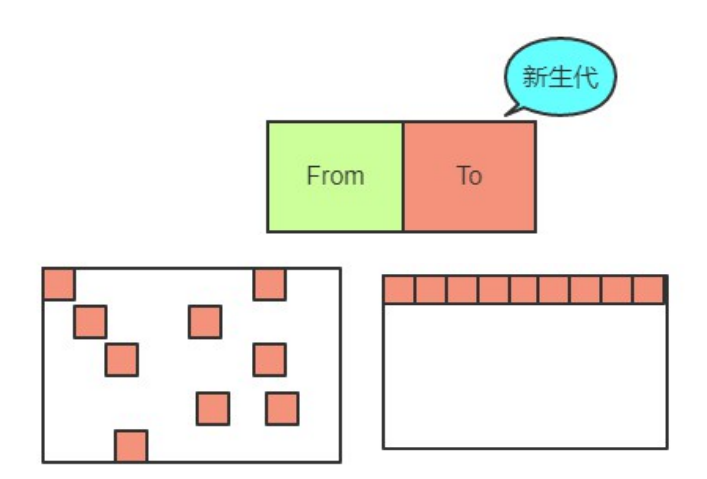
新生代内存空间分为 From(正在使用的内存)和 To (目前闲置的内存)。垃圾回收时使用 Scavenge 算法:检查From内存,将存活对象从头放置的方式复制到 To 内存(按理说复制的同时,From空间内存活对象的占用的内存应该释放掉),回收非存活对象,直到From内存空,From内存空间和To内存空间角色对调。由于新生代存储的是生命周期短的对象,对象较少,因此时间性能优秀,算法缺点是新生代内存使用率不超过新生代内存的一半。为何不直接将非存活对象回收?一个对象的堆内存分配是连续的,直接回收非存活对象会容易产生不够后续对象使用的内存碎片,内存利用率低。
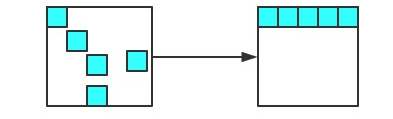
老生代内存,被晋升(1. 已经经历过一次 Scavenge 回收 2. 回收后To(闲置)空间的内存占用超过25%)的对象会被放入到老生代内存中。老生代垃圾回收(不使用 Scavenge 算法,老生代空间大,考虑内存利用率和复制耗时),采用标记清除算法:
- 标记-清除,遍历老生代中所有对象并做上标记,仅使用的变量以及被强引用的变量取消标记。标记结束后清除回收具有标记的变量对象。其中标记采用增量标记(为避免垃圾回收耗时阻塞时间过长,即将标记任务分为很多小的部分,小部分完成就暂停一下,直到标记阶段完成,如此,阻塞时间减少到原来的1/6);
- 整理内存碎片,清除阶段结束后把存活的对象全部往一端靠拢(移动对象,全过程最耗时操作)。
内存泄漏
堆栈溢出:指没有足够的内存空间申请。
内存泄漏指申请的内存执行完后没有及时的清理或者销毁,占用空闲内存。当内存泄漏过多就会导致堆栈溢出。一般是堆内存溢出。
常见内存泄漏的原因:
- 减少不正当的使用闭包,因为可能会造成内存泄漏
function fn() {
const test = new Array(1000).fill('');
return function () {
console.log(test);
return test;
}
}
let fnInner = fn();
fnInner();
/** fnInner() = null; // 置空外部引用 */
// More Tools -> Developer Tools -> Memory -> Allocation instrumentation on timeline- 隐式的全局变量可能导致内存泄漏
function fn() {
'use strict' // 函数内使用严格模式避免泄漏
// 没有声明的变量是隐式全局变量
test1 = new Array(1000).fill('');
// 函数内部 this 指向 window, test2 也是隐式全局变量
this.test2 = new Array(1000).fill('');
}
// More Tools -> Developer Tools -> Performance/Memory, 一般先在 Performance 面板录制页面内存占用情况随时间变化的图像,对内存泄漏有个直观的判断,然后在 Memory 面板定位问题发生的位置- 游离的 DOM 引用
<div id="root">
<ul id="ul">
<li></li>
<li></li>
<li id="li3"></li>
<li></li>
</ul>
</div>
<script>
let root = document.querySelector('#root');
let ul = document.querySelector('#ul');
let li = document.querySelector('#li3');
root.removeChild(ul);
ul = null; // 虽然置空了 ul 变量,但由于 li 变量引用了 ul 的子节点,所以 ul 元素依然不能被垃圾回收
li = null; // 已无变量引用,此时 ul 元素才可以垃圾回收
// 通过堆快照(Heap Snapshot),调试路径 Memory -> Heap Snapshot -> Take Snapshot,堆快照可以直接显示是否游离的 DOM 节点,只要在顶部过滤框 filter 输入 detached,如果过滤出东西,说明存在游离的 DOM 节点
</script>- 未清除的定时器和 requestAnimationFrame
let someResource = getData();
const timer = setInterval(() => {
const node = document.getElementById('Node');;
if (node) {
node.innerHTML = JSON.stringify(someResource);
}
}, 1000)- 组件卸载时未解除监听
created() {
eventBus.on('test', this.doSomething)
},
beforeDestroy() {
// eventBus.off('test');
},
methods: {
doSomething() {
// do something
}
}未清理的 console 输出:控制台会始终保持对 console 输出结果的引用,导致无法被垃圾回收
遗忘的 Map、Set 对象:Map、Set 是强引用,即一个对象被强引用所引用时,那么这个对象就不会被垃圾回收,若要能够回收,需置空 Map 和 Set。而 WeakMap 和 WeakSet 是弱引用,即一个对象只被弱引用所引用,则被认为是不可访问(或弱可访问)的,因此可能在任何时刻被回收。
并发模型与事件循环
JavaScript 有一个基于事件循环(Event Loop)的并发模型,负责浏览器和Node中执行代码、收集和处理事件以及执行队列中的子任务,是用于解决JavaScript单线程运行时可能会阻塞的一种机制。
事件循环是一个在 JavaScript 引擎等待任务,执行任务和进入休眠状态等待更多任务的状态之间转换的无限循环。Javascript 引擎大多数时候处于不执行任何操作即等待任务状态,仅在脚本加载完成/事件触发时执行。
渲染和执行JS是互斥的,都在渲染主线程中进行。执行JS时永远不会进行渲染(render)。仅在执行完成后才会绘制对 DOM 的更改。如果一项任务执行花费的时间过长,浏览器将无法执行其他任务,例如处理用户事件或渲染。因此,在一定时间后,浏览器会抛出一个如“页面未响应”之类的警报来建议终止这个任务。这种情况常发生在有大量复杂的计算或导致死循环的程序错误时。
任务分为宏任务(MacroTask或Task)和微任务(MicroTack),每个宏任务之后,JavaScript引擎会立即执行微任务队列中的所有任务,然后再执行其他的宏任务,或渲染,或进行其他任何操作。主动安排一个宏任务使用setTimeout/setInterval,主动安排一个微任务使用queueMicrotask。对于 v11.15.0+ 的Node表现和浏览器一致,执行完一个定时器任务立即执行微任务队列中的所有任务,而之前版本的Node在执行完定时器任务后先检查任务队列的队首是否定时器任务,是则保存微任务队列,优先执行该定时器任务,中途产生的微任务进入微任务队列,待定时器任务执行完再依次执行微任务队列。
// 使用嵌套的 setTimeout 调用来拆分 cpu 过载任务
let i = 0;
let start = Date.now();
function count() {
// 将调度(scheduling)移动到开头
if (i < 1e9 - 1e6) {
setTimeout(count); // 安排(schedule)新的调用
}
do {
i += 1;
} while (i % 1e6 !== 0);
if (i === 1e9) {
alert("Done in " + (Date.now() - start) + 'ms');
}
}
count();宏任务:script、setTimeout/setInterval(由计时线程计时,到期才放入队列中,且浏览器不会对同一个 setInterval 回调多次添加到任务队列,因此setInterval 的处理时长不能比设定的间隔长,否则 setInterval 将会没有间隔地重复执行)、setImmediate(Node.js)、I/O(Mouse Events、Keyboard Events、Network Events、文件读写)、UI Rendering(HTML Parsing)、MessageChannel等,多个宏任务形成宏任务队列。
// 实际上很多地方都见过这种技术
setTimeout(function repeatMe() {
// do something
setTimeout(repeatMe, 15);
// 执行完处理程序的内容后, 在末尾再间隔 15ms 来调用该程序,这样就能保证一定是15毫秒间隔的周期调用
}, 15);微任务:promise.then/catch/finally 的回调、await下一行、process.nextTick(Node.js)、MutationObserver、垃圾回收过程、queueMicrotask的回调。其中调用 process.nextTick() 时传入的 callback 会被入队到nextTick callback queue。其余微任务的 callback 会被入队到microtask callback queue,且nextTick callback queue的优先级高于 microtask callback queue。
浏览器事件(Event Loop)循环算法:
- 从宏任务队列中出队(dequeue)并执行最早的任务(例如script)。
- 依次执行当前微任务队列的所有任务。
- 如果有变更,则将变更渲染出来。
- 如果宏任务队列为空,则休眠直到出现宏任务。
- 转到步骤1。

Node.js事件循环算法:
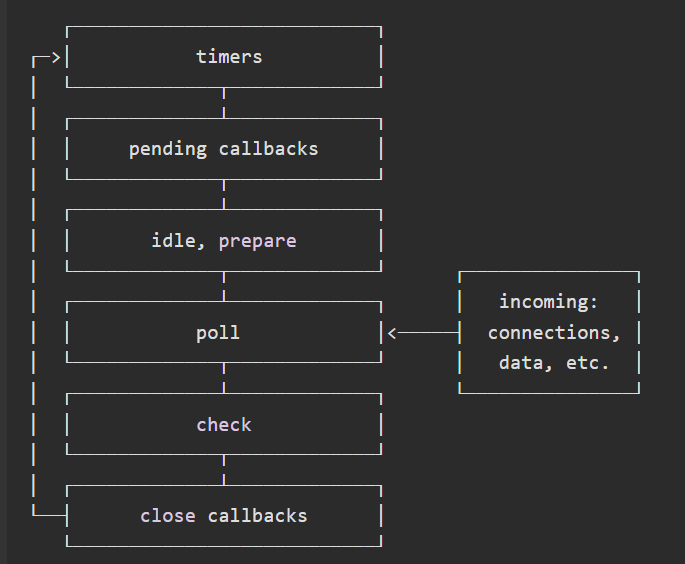
每个阶段都会有一个 callback queue 与之相对应。Event Loop会遍历这个 callback queue,执行里面的每一个callback。直到 callback queue 为空或者当前callback的执行数量超过了某个阈值为止,Event Loop才会移步到下一个阶段。事件循环示意图:
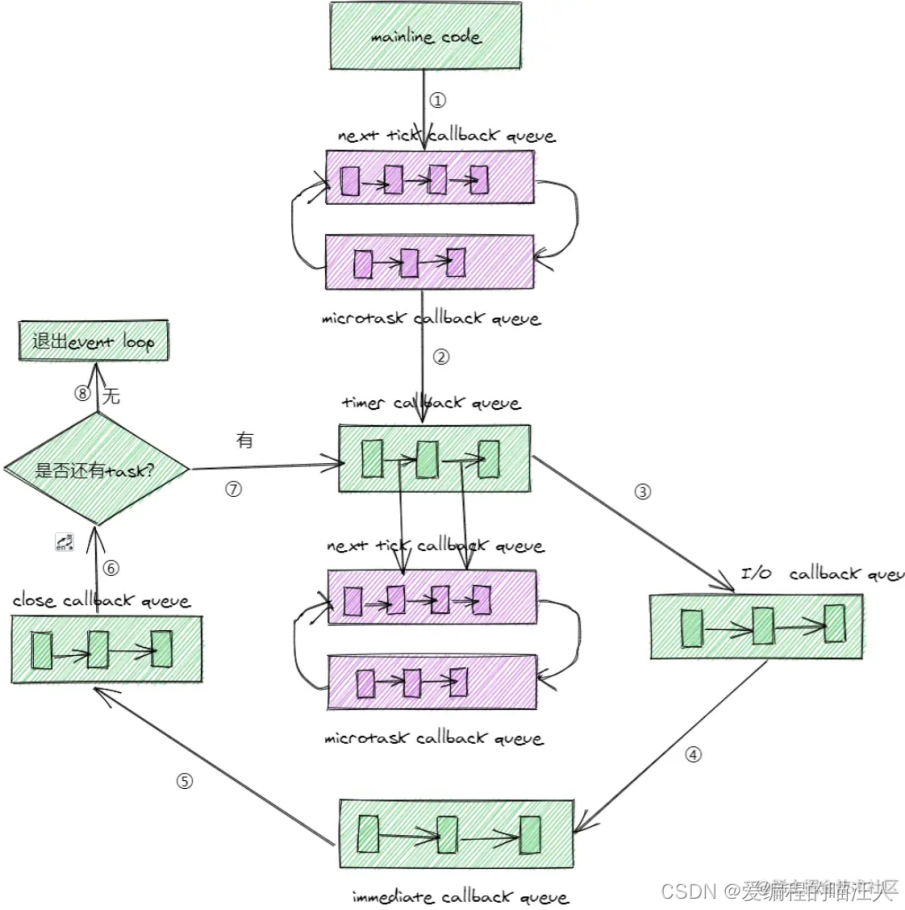
nodejs 事件循环涉及的队列: timer callback queue I/O callback queue immediate callback queue close callback queue nexTick callback queue microtask callback queue
- timer 阶段:此阶段执行 timer callback queue中的任务,调用 setTimeout 或者 setInterval 方法时传入的 callback 会在指定的延迟时间后入队到 timer callback queue。调用时候传入的延迟时间并不是回调确切执行的时间,会受到操作系统调度层面和其他callback函数调用耗时的影响,timer callback函数的执行只会比预定的时间晚。
- pending callbacks 阶段:执行上一次循环延迟到下一次循环迭代的I/O回调,可能是系统操作的回调,如TCP错误的类型。
- idle、prepare 阶段:只在node内部使用,不必理会。
- poll 阶段:timer callback queue为空进入poll阶段,会计算应该为I/O进行阻塞和轮询的时长,然后处理I/O callback queue中的事件(几乎所有回调,比如文件读写、网络请求等,除了 close callback 、定时器调度的 callback 和 setImmediate)。若I/O callback queue非空则依次执行;若I/O callback queue为空且存在setImmdiate回调,直接进入check阶段,否则阻塞轮询到超时后进入自动check阶段。
- check 阶段:I/O callback queue队列为空时,会立即进入该阶段,执行immediate callback queue。
- close callbacks 阶段:比如socket被突然关闭(如socket.destroy()),"close "事件将在这个阶段被发出。否则,它将通过process.nextTick()发出。此阶段执行close callbacks queue 的任务。
阐述⼀下 JS 的事件循环?
事件循环,是浏览器渲染主线程的工作⽅式,是异步的实现方式。
在 Chrome 的源码中,它开启⼀个不会结束的 for 循环,每次循环从消息队列中取出第⼀个任务执⾏,⽽其他所有线程(包括其他进程的线程、计时线程)只需要在合适的时候将任务加⼊到队列末尾即可。任务本身没有优先级,在队列中先进行出,不同的队列有优先级。过去把任务队列简单分为宏队列和微队列,目前已无法满足复杂的浏览器环境,而是更加灵活多变的处理方式,根据 W3C 最新的解释:每个任务有不同的类型,同类型的任务必须在同⼀个队列,不同类型的任务可以属于同一队列。不同任务队列有不同的优先级,在⼀次事件循环中,由浏览器自⾏决定取哪⼀个队列的任务。但浏览器必须有⼀个微队列,微队列的任务⼀定具有最高的优先级,必须优先所有其他任务执⾏。在目前 chrome 的实现中,至少还包括优先级「中」的延时队列和优先级「⾼」的交互队列,分别用于存放计时器到达后的回调任务,和用于存放用户操作后产生的事件处理任务。
如何理解 JS 的异步?
JS是⼀⻔单线程的语⾔,这是因为它运⾏在浏览器的渲染主线程中,⽽渲染主线程只有⼀个。⽽渲染主线程承担着诸多的⼯作,渲染⻚⾯、执⾏ JS 都在其中运⾏。如果使用同步的⽅式,就极有可能导致主线程产⽣阻塞,从⽽导致消息队列中的很多其他任务⽆法得到执⾏。这样⼀来,⼀⽅⾯会导致繁忙的主线程⽩⽩的消耗时间,另⼀⽅⾯导致⻚⾯⽆法及时更新,给⽤户造成卡死现象。所以浏览器采⽤异步的⽅式来避免。具体做法是当某些任务发⽣时,⽐如计时器、⽹络、事件监听,主线程将任务交给其他线程去处理,⾃身⽴即结束任务的执⾏,转⽽执⾏后续代码。当其他线程完成时,将事先传递的回调函数包装成任务,加⼊到消息队列的末尾排队,等待主线程调度执⾏。在这种异步模式下,浏览器永不阻塞,从⽽最⼤限度的保证了单线程的流畅运⾏。单线程是异步产生的原因。
JS 中的计时器能做到精确计时吗?
不⾏,因为:
- 计算机硬件没有原子钟,⽆法做到精确计时;
- 操作系统的计时函数本身就有少量偏差,由于 JS 的计时器最终调用的是操作系统的函数,也就携带了这些偏差;
- 按照 W3C 的标准,浏览器实现计时器时,如果嵌套层级 >= 5 层,则会带有 4 毫秒的最少时间,这样在计时时间少于 4 毫秒时⼜带来了偏差;
- 受事件循环的影响,计时器的回调函数只能在主线程空闲时运行,因此⼜带来了偏差。
浏览器事件相关
在 Web 中,事件在浏览器窗口中被触发并且通常被绑定到窗口内部的特定部分 — 可能是一个元素、一系列元素、document或者是window。每个可用的事件可设置事件处理器(或事件监听器),监听事件的发生,也就是事件触发时会运行的代码块。
实际上,JavaScript 网页上的事件机制不同于在其他环境中的事件机制。Nodejs中事件模型(nodejs event model)依赖定期监听事件的监听器和定期处理事件的处理器,比如使用on方法注册一个事件监听器,使用once方法注册一个在运行一次之后注销的监听器。浏览器插件(WebExtensions)的事件模型和网站的事件模型相似,唯一不同在于事件监听属性是小驼峰的且需要紧接着addListener。(比如browser.runtime.onMessage.addListener)。网络事件不是 JavaScript 语言的核心——它们被定义成内置于浏览器的 JavaScript APIs。
事件分为通用事件(比如几乎所有元素的onclick)和专门事件(video才有的onplay)。每个事件都使用继承自 Event 接口的对象来表示,可以包括额外的自定义成员属性及函数,以获取事件发生时相关的更多信息。
Event 接口表示在 DOM 中出现的事件。触发方式有
- 用户触发,比如鼠标、键盘事件。
- API生成,比如动画运行结束。
- 脚本触发,比如对元素调用HTMLElement.click或使用Even接口定义一些自定义事件,再使用 EventTarget.dispatchEvent方法将自定义事件派发往指定的目标(EventTarget)或直接使用EventTarget.dispatchEvent触发原生事件。和经由浏览器触发,并通过事件循环异步调用事件处理程序的“原生”事件不同,dispatchEvent() 会同步调用事件处理函数。在 dispatchEvent() 返回之前,所有监听该事件的事件处理程序将在代码继续前执行并返回。要向事件对象添加更多数据,可以使用 CustomEvent 接口,detail 属性可用于传递自定义数据。
事件处理函数内部,事件对象被自动以第一个参数传递给事件处理函数,以提供额外的功能和信息。大多数事件处理器的事件对象都有可用的标准属性和函数(方法),更高级的事件处理器的事件对象会添加一些专业属性,这些属性包含它们需要运行的额外数据。例如,媒体记录器 API 有一个 dataavailable 事件,它会在录制一些音频或视频时触发,并且可以用来保存它,或者回放。对应的ondataavailable处理程序的事件对象有一个可用的数据属性。
在事件处理程序内部,对象 this 始终等于 Event.currentTarget 的值且等于注册事件的对象,Event.target 则是对最初派发事件的目标的引用。
只读属性Event.isTrusted 表示当事件是由用户行为生成的时候,这个属性的值为 true ,而当事件是由脚本创建、修改、通过 EventTarget.dispatchEvent() 派发的时候,这个属性的值为 false 。
Event() 构造函数:

最开始,使用事件处理程序 HTML 属性(内联事件处理程序),会混用 HTML 和 JavaScript,而且没有直接移除事件的方式,不推荐使用,因为这样文档很难解析且不好维护。
DOM0级事件通过事件处理程序属性添加事件监听器,不允许给同一个监听器注册多个处理器,任何后面设置的都会尝试覆盖之前的,但具有更好的跨浏览器兼容性(IE8+)。
DOM 2级事件可以使用addEventListener添加事件处理程序,而且如果有需要,可以向同一类型的元素添加多个事件处理器,同时可以使用removeEventListener()移除某个事件处理程序,但需要保证 type, listener,capture/useCapture和addEventListener的相同。
过去 Netscape(网景)只使用事件捕获,而 Internet Explorer 只使用事件冒泡。DOM 2级事件规定的事件流(也叫事件传播)包括三个阶段,Event.eventPhase表示事件流当前处于哪一个阶段:
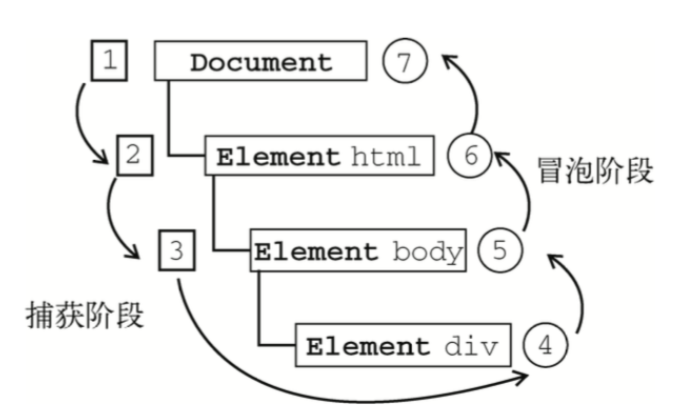
- 事件捕获阶段(Capture Phase):事件对象,从Window开始,然后Document, 然后是HTMLHtmlElement,直到目标元素的父元素,这个过程中通过addEventListener 注册为捕获模式(第三个参数为true)的事件处理程序会被调用。Event.eventPhase 为 1。
- 处于目标阶段(Target Phase):执行顺序会按照 addEventListener 的添加顺序决定,现添加先执行。Event.eventPhase为2。如果该事件只读属性的Event.bubbles为false,则不会进入冒泡阶段。如果多个事件监听器被附加到相同元素的相同事件类型上,会按其被添加的顺序被调用,如果如果在其中一个事件处理函数中执行Event. stopImmediatePropagation ,那么剩下的事件监听器都不会被调用。
- 事件冒泡阶段(Bubbling Phase):事件对象从父亲元素开始逆向向上传播回目标元素的祖先元素并最终到达包含元素 Window。这个过程中通过addEventListener 注册为冒泡模式(第三个参数为false)的事件处理程序会被调用。Event.eventPhase为3。可以通过在事件处理程序return之前设置Event.cancelBubble为true或调用Event.stopPropagation方法阻止事件冒泡。
调用方法Event.preventDefault或设置属性Event.returnValue为true来阻止事件的默认行为,比如阻止表单默认提交行为。为一个不支持取消即只读属性的Event.bubbles为true的事件调用preventDefault将没有效果。
事件委托依赖于事件冒泡,如果想要在大量子元素中单击任何一个都可以运行一段代码,可以将事件监听器设置在其父节点上,并让子节点上发生的事件冒泡到父节点上,而不是每个子节点单独设置事件监听器。
继承与原型链
JavaScript不是基于类的语言,而是基于原型的,本身不提供一个 class 实现,即使在 ES2015/ES6 中引入了 class 关键字(仅是一个语法糖)。
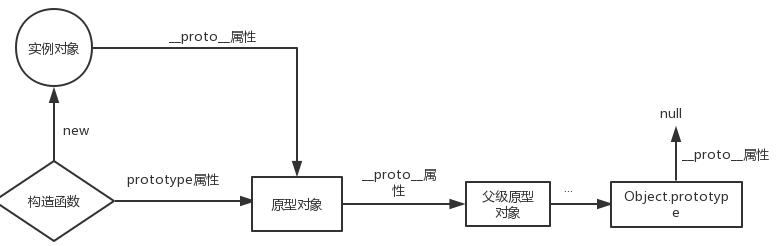
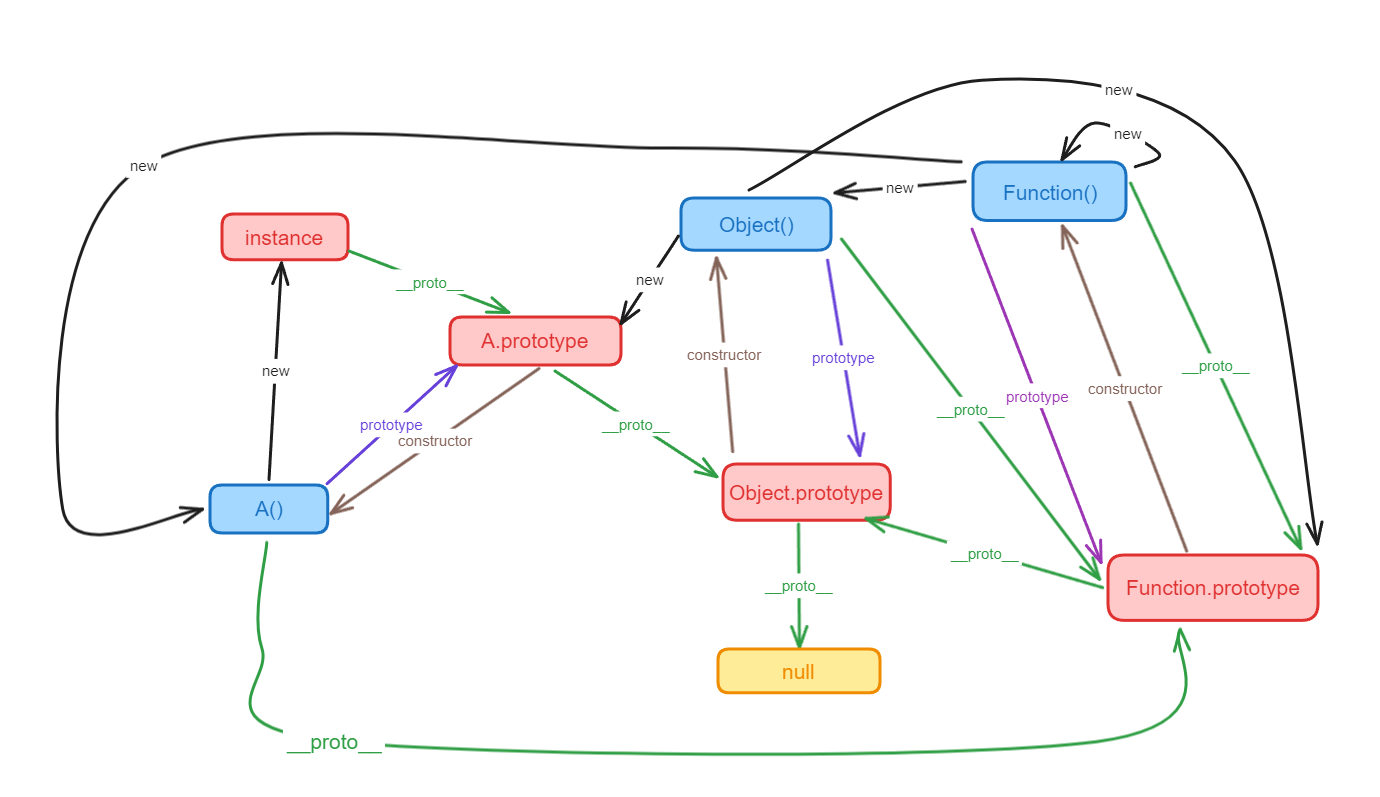
JavaScript中关于继承只有一种结构,即对象,每个实例对象(object)都有一个私有属性__proto__指向它的构造函数的原型对象(prototype ,也叫做函数原型即函数才有prototype,默认情况下,prototype是一个包括属性constructor的普通对象,其中属性constructor指向构造函数本身),该原型对象也有私有属性__proto__ 指向它的构造函数的原型对象(prototype ),层层向上,直到一个对象的__proto__为null(Object.prototype的__proto__为null)。__proto__即内部属性 [[prototype]],也叫做对象的隐式原型,默认情况下,__proto__指向创建该对象的构造函数的原型(prototype),__proto__可以访问,[[prototype]]无法直接访问,ES6开始可以通过 Object.getPrototypeOf() 和 Object.setPrototypeOf() 来访问和设置 [[prototype]]。Object.prototype是特殊的对象,不是被构造函数new出来的?。
原型链:每个JavaScript 对象通过__proto__属性指向它的构造函数的原型对象,__proto__ 将对象连接起来组成了原型链。
属性查找机制:沿着实例对象 —> 构造函数的原型对象prototype —> ... —>最顶级的原型对象Object.prototype的原型链查找,找到即停止,否则输出undefined。在原型链上查找属性比较耗时,对性能有副作用,尤其是在访问的属性不存在时。检查属性是否存在是不能检测值是否为undefined,有可能值恰好被设置为undefined。
属性修改机制:对象上直接修改属性只会修改或添加实例对象本身的属性,如果需要修改原型的属性时,则可以用: 构造函数.prototype.attribute = 2;但是这样会造成所有继承于该对象的实例的属性发生改变。
ES6 的 class语法糖可以使用extends很容易实现继承,而ES5可以利用Object.create()将子构造函数的prototype的__proto__设置为父构造函数的prototype,并且设置子构造函数的prototype的constructor属性为子构造函数,最后在子构造函数中调用父构造函数Parent.call(this),即寄生组合继承的方式(推荐使用):
function Parent(name) {
this.name = name;
}
function Child(name, age) {
Parent.call(this); // 调用父类的构造函数
this.age = age;
}
// 子类继承父类
Child.prototype = Object.create(Parent.prototype);
// 为了避免 Child.prototype.constructor 指向 Parent 的 prototype.constructor,需要设置 Child.prototype.constructor 为 Child
Child.prototype.constructor = Child;基于原型的编程是一种面向对象的编程风格,在这种风格中,类没有明确的定义,而是通过将属性和方法添加到另一个类的实例中,或者少数情况下将它们添加到一个空对象中来派生。简单地说:这种类型的风格允许创建一个对象,而不首先定义它的类。
原型的作用:首先,支持面向对象的语言必须要做到:能判定一个实例的类型。原型作为实现面向对象的手段之一,被JS采用。在JS中,通过原型就可以知晓某个对象从属哪个类型,即原型的存在避免了类型的丢失。此外,支持抽离实例的公共方法到原型上,避免将方法放到实例中,也能减少内存消耗。
面向对象的设计一定是好的设计吗?
不一定,从继承的角度说,这一设计是存在巨大隐患的,因为继承最大的问题在于属性继承的不可选择性。而解决的趋势是使用组合的设计模式:面向组合就是先设计一系列零件,然后将这些零件进行拼装,来形成不同的实例或者类。
猴子补丁:在函数原型中加入成员,以增强对象的功能,猴子补丁会导致原型污染,使用需谨慎。
Classes相关
类是创建对象的模板。它们将数据与代码封装起来,以便对这些数据进行处理。类也是Function的实例。JS中的类是建立在原型基础上的,但也有一些语法和语义,与ES5类的语义不尽相同。
通过class创建的构造函数只能通过new的方式调用。
类定义语法有两个组成部分:类表达式和类声明。无法重新定义类,否则会抛出SyntaxError错误。
类声明是指使用带有class关键字的类名声明一个类,与函数声明的重要区别是不会提升,在声明之前访问类将会抛出ReferenceError异常。
类表达式可以命名或不命名,类表达式本身不提升,提升的是前面var/let/const声明的的变量。命名类表达式的名称,可以通过类的静态属性name访问,与函数表达式相同,匿名类表达式的name值是首次赋值目标的变量名,命名类表达式则是class关键字后的名称。
一个类的类体是一对{} 中的部分,用于定义类成员(静态方法、原型方法、构造函数、getter、setter)。类声明和类表达式的主体都执行在严格模式下。
constructor
constructor方法是用于创建和初始化class创建的对象的特殊方法,一个类只能有一个constructor,否则将抛出SyntaxError异常。如果没有显式指定构造方法,则会添加默认的 constructor 方法,对于基类默认的构造函数是constructor() {};对于派生类,默认构造函数是constructor(...args) {super(...args);}。
在构造函数方法体内,可以通过this访问正在创建的对象,通过new.target访问用new调用的类。在构造函数执行之前,方法(包括getters和setters)和原型链已经在this上初始化了,所以甚至可以在基类的构造函数中访问派生类的方法,然而,如果这些派生类的方法中使用到this,由于this还没有被完全初始化,这意味着在基类的构造函数中读取派生类的公共字段将导致未定义以及读取派生类的私有字段将导致TypeError,但在派生类构造函数中可以读取。
构造方法中可以使用 super 关键字来调用父类的构造方法,而且在派生类中,必须先调用 super 才能使用 "this"。super()调用的是当前类本身的原型的构造函数,因此如果改变的是当前类本身的原型,super()将调用新原型的构造函数,而如果改变当前类的prototype属性并不影响super()调用哪个构造函数。
构造函数方法可以有返回值,对于基类可以返回非object值,只不过会被忽略;对于派生类,必须返回object或undefined,否则将会抛出TypeError错误。如果基类的构造函数返回一个对象,则该对象将用作定义派生类的类字段的 this 值,这个技巧称为“返回覆盖”,它允许派生类的字段(包括私有字段)被定义在不相关的对象上。
构造函数必须是文字名称constructor,不能是计算属性[“constructor”],否则会被定义为原型上的一个constructor方法,不会在new的时候调用。
extends
extends关键字(class ChildClass extends ParentClass { ... })用于类声明或者类表达式中创建一个派生类。任何可以用new调用的构造函数都可以作为ParentClass,ParentClass的prototype属性必须是 Object 或 null。extends 将分别设置ChildClass 和 ChildClass.prototype 的原型为ParentClass和ParentClass.prototype,分别使得静态方法与属性和原型方法与属性分别可以被继承。extends 的右侧不必是标识符,可以使用任何计算结果为可被new调用的构造函数的表达式。
由于extends右侧只能有一个单基类,因此直接多重继承是不可能的。定义一个以基类作为输入和一个继承该基类的派生类作为输出的函数可以用于在 ECMAScript 中实现 Mix-ins 或抽象子类。
// 抽象子类 1 或 min-ins 1
const calculatorMixin = (Base) => class extends Base {
calc() { };
};
// 抽象子类 1 或 min-ins 1
const randomizerMixin = (Base) => class extends Base {
randomize() { };
};
// 多重继承抽象子类1 或 mix-ins 1 与 抽象子类 2 或 mix-ins 2
class Foo { };
class Bar extends calculatorMixin(randomizerMixin(Foo)) { };super
super 关键字用于访问对象实例或类本身的原型([[Prototype]])上的属性和方法,或调用基类的构造函数,遵循原型链属性查找机制。super 关键字有且只有两种使用方式:作为“函数调用”(super(...args)),或作为“属性查询”(super.prop 和 super[expr]),试图访问 super 本身会导致 SyntaxError异常。
函数调用(super(...args))形式可以在派生类的构造函数体中使用,但必须在使用 this 关键字之前和构造函数返回之前调用super,否则会在实例化时抛出ReferenceError错误。
属性查询形式(super.prop 和 super[expr])可以用来访问派生类的 [[Prototype]](即基类)的公有静态方法和属性(即基类的公有静态方法和属性)或派生类的prototype上的 [[Prototype]](即基类的prototype)的方法(即基类中定义的公有实例方法)。在类字段声明区域声明公有字段时,对于公有静态字段,super的引用是基类的构造函数;对于公有实例字段,super的引用是基类的prototype对象,由于实例字段是在实例上设置的,不能用 super 来访问父类的实例字段,只能是基类的公有实例方法。不能使用 delete 操作符加上 super.prop 或者 super[expr] 去删除父类的属性,这样做会抛出 ReferenceError。
属性查询形式(super.prop 和 super[expr])还可以用来访问对象字面量的 [[Prototype]] 的方法和属性。
属性查询的行为类似于Reflect.get(Object.getPrototypeOf(objectLiteral), prop或[expr], this)意味着该属性总是在对象字面量/类声明的原型链上寻找,取消绑定和重新绑定方法(即赋值给一个变量)不会改变 super 的引用。
属性设置(super.prop = value 和 super[expr] = value)的行为类似于Reflect.set(Object.getPrototypeOf(objectLiteral), prop或[expr], value, this),由于this是当前实例对象,因此它是在当前实例对象上设置属性,而且会调用setter,意味着不能重写不可写的属性。
属性与方法
实例的属性必须定义在类的方法里(准确的说是constructor方法)。静态属性必须类体外在CLASSNAME上定义。原型属性必须类体外在CLASSNAME.prototype上定义。
类体内通过 static 关键字定义公有静态字段和公有静态方法,没有设定初始化的公有静态字段将默认被初始化为 undefined,可以通过类本身的原型链访问它们。在类的构造函数和公有实例方法中访问静态方法,只能使用类名CLASSNAME.STATIC_METHOD_NAME或者使用构造函数的属性this.constructor.STATIC_METHOD_NAME。在类的静态方法中访问同一个类中的其他静态方法,可直接使用 this.STATIC_METHOD_NAME 关键字。在类体外访问静态方法,只能使用类名CLASSNAME.STATIC_METHOD_NAME。在派生类中可以使用super.STATIC_METHOD_NAME访问基类的静态方法。在字段声明区域初始化公有静态字段时,this 指向的是类的构造函数,或者使用类名本身,派生类中此处可以使用 super 来访问基类的构造函数,由此访问基类的公有静态方法和公有静态字段。公有静态方法中的this也是类的构造函数,当方法调用的上下文不是类的构造函数,则方法内的this指向undefined。公有静态方法是在类的声明阶段用 Object.defineProperty方法添加到类的构造函数上的,其属性特性是可写、不可枚举和可配置的。公有静态字段是在类的声明阶段用 Object.defineProperty方法添加到类的构造函数上的,其属性特性是可写、可枚举和可配置的。
公有实例方法是在类的声明阶段用 Object.defineProperty方法添加到类的prototype中,采用方法定义简写语法(可以使用普通方法,生成器方法(*generatorMethod(){})、异步方法(async asyncMethod(){})和异步生成器方法(async *asyncGeneratorMethod(){}),getter,setter)。公有实例方法中this指向实例化对象,当方法调用的上下文不是实例对象本身,则this指向undefined。派生类的公有实例方法中可以使用 super 访问到基类的prototype,由此调用基类的公有实例方法。公有实例方法不是构造函数,尝试实例化它们将抛出TypeError异常。其属性特性是可写、不可枚举和可配置的。
公有实例字段是在基类的构造函数运行之前或在派生类的super()返回之后用Object.defineProperty添加到实例对象上的(在基类的构造函数中访问派生类的公有实例字段是未定义(undefiend)),没有设定初始化的字段将默认被初始化为 undefined。和实例的属性一样,公有实例字段名可以使用计算属性([key])。在字段声明区域初始化公有实例字段时,this 指向的是实例对象,派生类中此处可以使用 super 来访问基类的prototype,由此调用基类的公有实例方法。派生类中的公有实例字段声明不会调用基类中的 setter,相反,在构造函数中使用this初始化的属性会调用基类中的setter。其属性特性是可写、可枚举和可配置的。公有实例方法和公有实例字段则是可以通过类实例对象的原型链访问。
类字段在默认情况下是公有的,但可以使用增加哈希前缀 # 的方法来定义私有类字段,与公有字段(方法)的区别在于不参与对应原型的继承。私有字段不能通过在之后赋值来创建它们,这种方式只适用普通属性。
私有字段(方法)包括私有实例字段(方法)和私有静态字段(方法)。
私有实例字段(方法)在类声明的构造方法中可被访问。从实例对象上访问私有实例字段(方法)、类体内在未声明的情况下访问或设置私有实例字段、或尝试使用 delete 移除声明的私有实例字段都会抛出语法错误。可以使用 in 运算符检查私有实例字段(或私有实例方法)是否存在,当私有实例字段或私有实例方法存在时,运算符返回 true,否则返回 false。和公有实例字段一样,私有实例字段是在基类的构造函数运行之前或在派生类的super()返回之后用Object.defineProperty添加到实例对象上的(在基类的构造函数中访问派生类的公有实例字段是未定义(undefiend))。私有实例方法则是在类的声明阶段添加到到实例对象上的,但不能在实例对象上访问。私有实例方法可以是生成器方法、异步方法或异步生成器方法,也可以是私有的 getter 和 setter。
私有静态字段或方法是在类的声明阶段用 Object.defineProperty方法添加到类的构造函数上的。只有定义该私有静态字段或方法的类能访问该字段,直接使用派生类访问会抛出TypeError异常。
严格模式
JavaScript 的严格模式(strict mode)是使用受限制的 JavaScript 的一种方式,从而隐式地退出正常模式(sloppy mode,也被翻译为马虎模式/稀松模式/懒散模式)也就是非严格模式。通过在脚本文件/函数开头添加 "use strict"; 声明,即可渐进式地启用严格模式。
严格模式对正常的 JavaScript 语义做出更改:
- 严格模式通过抛出错误来消除了一些原有静默错误。
- 严格模式修复了一些导致 JavaScript 引擎难以执行优化的缺陷:有时候,相同的代码,严格模式可以比非严格模式下运行得更快。
- 严格模式禁用了在 ECMAScript 的未来版本中可能会定义的一些语法。
严格模式下的改变:
- 严格模式下,变量必须声明后使用。
- 严格模式下,引起静默失败的赋值操作(比如给NaN赋值,给不可写属性赋值,给不可扩展对象添加新属性,删除不可配置的属性,给原始值设置属性)会抛出异常。
- 严格模式要求函数的参数名唯一。
- 严格模式要求一个对象内的所有属性名在对象内必须唯一。
- 严格模式禁止八进制数字语法。
- 严格模式禁用 with。
- 严格模式下的 eval 不再为上层作用域引入新变量。
- 严格模式禁止删除声明变量。
- 严格模式禁止eval 和 arguments 重新赋值。函数参数的值与 arguments 对象的值任何一方的修改都不影响另一方。不支持使用 arguments.callee。不支持使用arguments.caller
- 在严格模式下通过this传递给一个函数的值不会被强制转换为一个对象。禁止 this 指向全局对象
- 在严格模式禁止使用 func.caller 和 func.arguments 获取函数调用的堆栈。
- 在严格模式中一部分字符变成了保留的关键字。这些字符包括implements, interface, let, package, private, protected, public, static和yield。
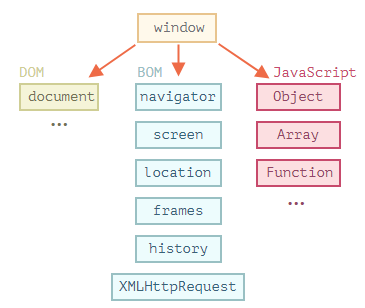
BOM 相关
BOM 即浏览器对象模型,提供除处理DOM外所有内容的属性与方法。BOM、DOM以及Javascript Object 构成浏览器主机环境的所有操作,都是根对象window子属性。
navigator 对象提供了有关浏览器和操作系统的背景信息,其中属性navigator.platform — 关于平台(可以帮助区分 Windows/Linux/Mac 等)。
- navigator.userAgent — 关于当前浏览器。
- navigator.connection 是只读的,返回网络连接状态 NetworkInformation 对象,包括以下属性:
- downlink(网络下行速度):以 Mb/s 为单位的有效带宽,并保留该值为 25kb/s 的最接近的整数倍。该值基于最近监测的保持活跃连接的应用层吞吐量,排除了到私有地址空间的连接。当缺少最近的带宽测量数据时,该属性由底层连接技术属性决定。因此会动态更新。
- effectiveType(网络类型):连接的有效类型,表示“slow-2g”、“2g”、“3g”或“4g”之一。该值是使用最近观察到的rtt和downlink值来确定的。
- onchange(有值代表网络状态变更)
- rtt(估算的往返时间):当前连接下评估的往返时延(RTT, round-trip time),并保留该值为25千分秒的最接近的整数倍。该值基于最近使用中被监测的最近保持活跃连接的应用层上的 RTT 测量值。它排除了到私有地址空间的连接。如果没有最近的测量数据,该值就基于底层连接技术的属性。因此会动态更新。
- saveData(打开/请求数据保护模式):boolean类型,如果用户设备上设置了减少数据使用的选项时返回 true。
navigator.connection.onchange 事件在连接信息发生变化时触发,该事件由 NetworkInformation 对象接收。
navigator.onLine:boolean类型,浏览器的在线状态,true 表示在线,false 表示离线。当浏览器获得网络访问权限并且navigator.onLine的值切换为 true 时,将触发 window 的的online事件。当浏览器无法访问网络并且navigator.onLine的值切换为 false 时,会触发 window 的offline事件。online事件和offline事件的eventTarget也可以是HTMLBodyElement 或 HTMLFrameSetElement 或 SVGSVGElement。
location 对象提供有关url处理的属性和方法:
- location.href 读取或设置当前url,设置即发生页面跳转
- location.hash 读取或设置当前url的hash(包括#,如果设置第一个不是#会自动加上,如果设置多个#即多个#),设置即发生页面内锚定位
- location.search 读取或设置当前url的查询部分(包括?,和hash一样会自动加上并可多个显示),设置即发生页面请求和跳转
- location.reload() 重新载入当前文档,location.replace() 替换当前文档,location.assign()加载新的文档,都不存在后退至当前文档。
window.postMessage
window.postMessage() 方法可以安全地实现跨域通信。当前窗口可以获得对另一个窗口targetWindow的引用(比如 iframe 的 contentWindow 属性、执行window.open返回的窗口对象、或者是window.frames中的某一个)。
- 在需要发送消息的所在页面调用 targetWindow.postMessage() 方法给targetWindow发送MessageEvent 消息。即targetWindow.postMessage(message, targetOrigin[, transfer]):
- message将要发送到其他 window 的数据。它将会被结构化克隆算法序列化。
- targetOrigin指定哪些页面的窗口能接收到消息事件,其值可以是字符串"*"(表示无限制)或者一个 URI,最好是使用明确的URI。目标窗口所在页面的协议、主机地址或端口这三者的任意一项不匹配 targetOrigin 提供的值,那么消息就不会被发送;用来防止消息被恶意的第三方截获。
- transfer,可选,是一串和 message 同时传递的 Transferable 对象。这些对象的所有权将被转移给消息的接收方,而发送一方将不再保有所有权。
- 接收消息的窗口所在页面内使用targetWindow可以使用window.addEventListener监听message事件并接收MessageEvent消息。即window.addEventListener(‘message’, receiveMessage, false),其中receiveMessage方法的参数event的属性有:
- data:从其他 window 中传递过来的对象。
- origin:调用 postMessage 时消息发送方窗口所在页面的URI
- source对发送消息所在页面的window的引用;
window.open
window.open(url, target, windowFeatures)用指定的名称将指定的资源加载到新的或已存在的浏览上下文(标签、窗口或 iframe)中。返回一个 WindowProxy 对象。只要符合同源策略安全要求,返回的引用就可用于访问新窗口的属性和方法。如果浏览器无法打开新的浏览上下文,例如因为它被浏览器弹出窗口阻止程序阻止,则返回 null,因为现代浏览器已内置弹出窗口阻止程序,将弹出窗口的打开限制在直接响应用户输入的情况下,而在点击之外打开的弹出窗口可能会显示通知,让用户选择启用或放弃。远程 URL 不会立即加载。当 window.open() 返回时,窗口始终包含 about:blank。URL 的实际获取会被推迟,并在当前脚本块执行完毕后开始。窗口的创建和引用资源的加载是异步完成的。参数如下:
- url:可选,一个字符串,表示要加载的资源的 URL 或路径。如果指定空字符串("")或省略此参数,则会在目标浏览上下文中打开一个空白页。如果新打开的浏览上下文不共享相同的源,则打开脚本将无法与浏览上下文的内容进行交互(读取或写入)。
- target:可选,一个不含空格的字符串,用于指定加载资源的浏览上下文的名称。如果该名称无法识别现有的上下文,则会创建一个新的上下文,并赋予指定的名称。还可以使用特殊的 target 关键字:_self、_blank、_parent 和 _top。该名称可用作
<a>或<form>元素的 target 属性。使用 "_blank" 作为 target 属性值会在用户桌面上创建多个新的无名窗口,这些窗口无法循环使用或重复使用。请尝试为 target 属性提供一个有意义的名称,并在页面上重复使用这样的 target 属性,这样点击另一个链接就可以在一个已经创建和渲染的窗口中加载引用的资源(因此可以加快用户的操作速度)。 - windowFeatures:可选,一个字符串,包含以逗号分隔的窗口特性列表,形式为 name=value,布尔特性则仅为 name。这些特性包括窗口的默认大小和位置、是否打开最小弹出窗口等选项,windowFeatures 中要求的位置(top、left)和尺寸(width、height)值,如果其中任何一个值不允许在用户操作系统应用程序的工作区内呈现整个浏览器弹出窗口,则将被更正。即新弹出窗口的任何部分最初都不能置于屏幕之外。:
- popup:如果启用此特性,则要求使用最小弹出窗口。弹出窗口中包含的用户界面功能将由浏览器自动决定,一般只包括地址栏。如果未启用 popup,也没有声明窗口特性,则新的浏览上下文将是一个标签页。在 windowFeatures 参数中指定除 noopener 或 noreferrer 以外的任何特性,也会产生请求弹出窗口的效果。要启用该功能,可以不指定popup,或者将其设置为 yes、1 或 true。比如,popup=yes、popup=1、popup=true 和 popup 都具有相同的结果。
- width 或 innerWidth:指定内容区域(包括滚动条)的宽度。最小要求值为 100。
- height 或 innerHeight:指定内容区域(包括滚动条)的高度。最小要求值为 100。
- left 或 screenX:指定从用户操作系统定义的工作区左侧到新窗口生成位置的距离(以像素为单位)。
- top 或 screenY:指定从用户操作系统定义的工作区顶部到新窗口生成位置的距离(以像素为单位)。
- noopener:如果设置了此特性,新窗口将无法通过 Window.opener 访问原窗口,并返回 null。使用 noopener 时,在决定是否打开新的浏览上下文时,除 _top、_self 和 _parent 以外的非空目标名称会像 _blank 一样处理。
- noreferrer:如果设置了此特性,浏览器将省略 Referer 标头,并将 noopener 设为 true。
最好不要使用 window.open(),因为:
- 现代浏览器提供弹出窗口阻止功能
- 现代浏览器提供选项卡浏览功能,而支持选项卡功能的浏览器用户在大多数情况下更喜欢打开新选项卡,而不是打开新窗口。
- 用户可以使用浏览器的内置功能或扩展功能来选择在新窗口、同一窗口、新标签页、同一标签页或后台打开链接。使用 window.open() 强制以特定方式打开链接会使用户感到困惑,并忽略他们的习惯。
- 弹出窗口没有菜单工具栏,而新标签页使用浏览器窗口的用户界面;因此,许多用户更喜欢标签页浏览,因为界面保持稳定。
DOM相关
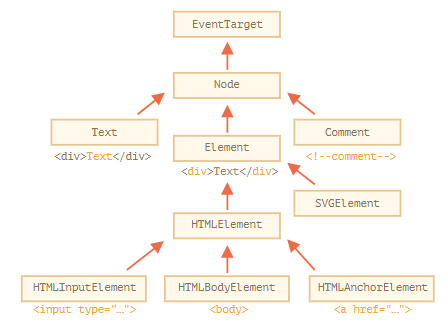
DOM 即文档对象模型(document,属性 nodeType=9),提供更改或创建页面上任何内容的属性与方法。HTML标签(元素节点,属性 nodeType=1)都是可操作的JavaScript对象,同时标签内文本(文本节点,属性 nodeType=3)也是对象(document.body, document.head分别对应body标签和head标签)。
DOM节点的原型链(注意这些都是构造函数,原型链上是指他们的prototype对象):DOM节点对象=> HTMLSpecificElement(提供特定于具体类别元素的属性,Specific比如是Input/Body/Anchor) => HTMLElement(提供了通用(common)的 HTML 元素方法(以及 getter 和 setter)) => Element(提供通用(generic)元素方法) => Node (提供通用 DOM 节点属性)=> EventTarget(为事件(包括事件本身)提供支持) => Object。 console.log(element) 显示元素的 DOM 树。 console.dir(element) 将元素显示为 DOM 对象,非常适合探索其属性。
文本节点即DOM树的叶子,document即DOM树的根(声明 + <html>)。<html> = document.documentElement。<head> </head>之前的空格和换行符均被忽略,<body></body>后的文本内容(包括空格和换行符均会被移到其内末尾)。<table></table>标签即使没写<tbody></tbody>也有<tbody></tbody>,因为浏览器会自动创建。
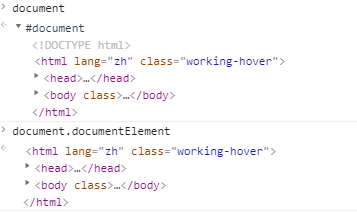
注意:脚本若是在 <head> 中,那么脚本是访问不到 document.body 元素的(返回null) 常用节点:文档节点、元素节点、属性节点、文本节点、注释节点 元素标签上的特性 (attributes)和DOM对象属性(properties)并不完全是一一对应,对于元素的标准特性存在DOM 属性,非标准特性则不存在对应DOM属性。但所有特性都可以通过使用以下方法进行访问:
element.hasAttribute(name) — 检查特性是否存在。
element.getAttribute(name) — 获取这个特性值。
element.setAttribute(name, value) — 设置这个特性值。
element.removeAttribute(name) — 移除这个特性。
element.attributes:读取所有特性集合——每个特性是具有 name 和 value 的对象。
element.dataset.*:非标准特性data-*对应的 DOM属性。
element.className :获取或设置 "class" 特性(attribute),设置时替换类中的整个字符串
element.classList:获取element的类可迭代集合。具有方法:
- add/remove(class):添加/移除类。
- toggle(class):如果类不存在就添加类,存在就移除它。
- contains(class):检查给定类,返回 true/false。
element.style.*:仅获取或设置对应于标签上 "style" 特性(attribute)的样式key的值,多词(multi-word)属性,使用驼峰式 camelCase;对于样式的移除,应设置为空字符串。多样式设置,可用特殊属性 element.style.cssText/element.setAttribute来设置(此方法完全替换原有样式),而不是设置只读对象element.style。
getComputedStyle(element,[pseudo]):获取element的CSS样式对象(不仅是标签的"style" 特性(attribute)),返回对象的属性值是解析样式值,为避免访问失效,访问该对象的属性的名字应是完整名。注意:该对象无法访问:visited伪类,目的是为了防止不好的网站检测用户是否访问过链接。此方法获取的width/height值是CSS-width/height,会取决于box-sizing样式,同时会受到浏览器差异影响,因此元素的宽高应该使用DOM几何属性(clientWidth/clientHeight等)来代替获取。
当一个标准特性被修改,对应的DOM属性自动会更新,反之亦然(存在特例:input.value 只能从特性同步到属性,反之不行)。DOM 属性和方法的行为与常规的 Javascript 对象一样。DOM属性值类型是多种的,而元素特性值一定是字符串类型。对于href特性值是标签上的值,而对应的DOM属性href值总是完整url。
节点的导航API:
element.childNodes:返回element的直接子节点可迭代类数组(包括文本节点),其实是集合,集合遍历应使用for...of...而不是for...in...,但最好建议使用子节点的nextSibling属性循环遍历,比使用childNodes类数组效率高。DOM集合是只读且实时的,
element.hasChildNodes():判断element是否具有直接子节点
element.firstChild 和 lastChild:分别访问第一个和最后一个直接子节点
element.previousSibling和nextSibling:分别访问element的上一兄弟节点和下一兄弟节点
element.parentNode:访问element的父节点
element.children :仅返回作为直接子元素节点。
element.firstElementChild,lastElementChild :第一个和最后一个子元素节点。
element.previousElementSibling,nextElementSibling :兄弟元素节点。
element.parentElement:返回父元素节点

node.nodeName 或者 element.tagName 属性中读取它的标签名(返回值都是全大写),后者只能用于元素节点。
element.innerHTML: 获取或设置element元素内的HTML内容(即使是 += 也是完全重写——移除之前的HTML,再写入旧HTML+新HTML的HTML),此方法设置的script不会执行,标签作为HTML处理(即不存在XSS攻击)。
element.outerHTML:获取包括元素本身的HTML内容,设置此属性不会修改element,而是替换,访问element仍然还是原来的元素。
nonElement.nodeValue/data:访问或设置非元素节点(文本、注释)内的内容,建议使用后者 data。
element.textContent:获取元素内除去所有标签的文本内容,设置此属性时标签作为文本内容处理。
element.hidden:设置元素是否可见(和 display:none等价,但更简洁),作为 HTML特性即写在标签上默认值为true——隐藏。
table元素更多API(除上述之外): tableElemt.rows:<tr> 元素的集合。
table.caption/tHead/tFoot :引用元素 <caption>,<thead>,<tfoot>。
table.tBodies : <tbody>元素的集合(只要有tabel节点,至少会有一个—浏览器自动生成)。
tr.cells:在给定 <tr> 中的 <td> 和 <th> 单元格的集合。
tr.sectionRowIndex — 给定的 <tr> 在封闭的 <thead>/<tbody>/<tfoot> 中的位置(索引)。
tr.rowIndex — 在整个表格中 <tr> 的编号(包括表格的所有行)。
td/th.cellIndex — 在封闭的 <tr>或 <td> 中单元格的编号。
按选择器搜索元素节点API:
document.getElementById(id) 或者只使用 id:后者不建议使用(因为可能造成命名冲突),设置在元素标签上属性id=’ ‘ 应唯一,否则方法搜索返回的可能是该id的一个随机元素,注意没有 element.getElementById()。
element.querySelectorAll(css)和element.querySelector(css):分别返回指定CSS选择器匹配的所有元素静态集合和第一个元素,后者虽结果和element.querySelectorAll(css)[0]相同,但效率更高。
element.closest(css):查找与 CSS 选择器匹配的最近的祖先。element自己也会被搜索。
element.matches(css):不会查找任何内容,它只会检查 element 是否与给定的 CSS 选择器匹配。它返回 true 或 false。可用于过滤元素。
element.getElementsByTagName(tag):查找具有给定标签的元素,并返回它们的实时集合。tag 参数也可以是对于“任何标签”的星号 "*"。
element.getElementsByClassName(className):返回具有给定CSS类的元素实时集合。
document.getElementsByName(name) :返回在文档范围内具有给定 name 特性的元素实时集合。很少使用。
DOM 节点创建方法:
- document.createElement(tag):根据给定标签创建元素节点
- document.createTextNode(text):根据给定文本创建文本节点
DOM节点插入方法(这5个均支持插入多个):
- node.append(...nodes or strings) :在 node 末尾 插入节点或字符串
- node.prepend(...nodes or strings) : 在 node 开头 插入节点或字符串
- node.before(...nodes or strings) : 在 node 前面 插入节点或字符串
- node.after(...nodes or strings) :在 node 后面 插入节点或字符串
- node.replaceWith(...nodes or strings) :将 node 替换为给定的节点或字符串。
这5种方法的字符串插入表现都与element.textContent相同,不会进行标签转义。
element.insertAdjacentHTML(where, html):将html作为HTML字符串插入到where指定的位置。element.insertAdjacentText(where, text)和
element.insertAdjacentElement(where, element)和它语法一样,只是前者作为 文本插入,后者插入元素。参数 where 必须是其中之一:

DOM节点移除方法:
node.remove():移除node节点
对于以上所有的插入方法,在移动元素插入另一位置的时候都会自动从旧位置删除该节点,不必手动remove()。
DOM节点克隆方法: element.cloneNode(true/false): true即深克隆(所有特性和子元素),false即浅克隆(不包括子元素)
DocumentFragment 是一个特殊的传递节点列表的包装器的 DOM 节点。可向其附加节点,当它被作为节点插入时是插入这些附加的节点。
文本合成事件
Element.compositionstart当文本合成系统(例如输入法编辑器)启动新的合成会话(拼音输入)时,会触发该事件。
Element.compositionupdate当在由文本合成系统(例如输入法编辑器)控制的文本合成会话(拼音输入)的上下文中接收到新字符时,将触发该事件。
Element.compositionend当文本合成系统(例如输入法编辑器)完成或取消当前合成会话(拼音输入)时,将触发该事件。
其中 Chrome 浏览器的触发顺序为 compositionstart ->input ->compositionend,其他浏览器为compositionstart ->compositionend ->input。
import React from 'react';
// eslint-disable-next-line max-len
type InputProps = React.DetailedHTMLProps<React.InputHTMLAttributes<HTMLInputElement>, HTMLInputElement>;
/**
* 封装支持合成输入的文本 input
*/
const Input = React.forwardRef<HTMLInputElement, InputProps>((props, ref) => {
const [composing, setComposing] = React.useState(false);
return (
<input
ref={ref}
onChange={(e) => {
if (!composing) {
// eslint-disable-next-line react/prop-types
props.onChange?.(e);
}
}}
onCompositionStart={() => {
setComposing(true);
}}
onCompositionEnd={(e) => {
if (composing) {
setComposing(false);
const inputEvent = new Event('input', { bubbles: true, cancelable: false });
e.target.dispatchEvent(inputEvent);
}
}}
// eslint-disable-next-line react/jsx-props-no-spreading
{...props}
/>
);
});
export default Input;元素滚动相关
Element. scrollIntoView(alignToTop)或Element. scrollIntoView(scrollIntoViewOptions) 方法会滚动元素的父容器,使调用 scrollIntoView() 的元素对用户可见。可选参数alignToTop如果为 true,元素的顶端将和其所在滚动区的可视区域的顶端对齐,即可选参数scrollIntoViewOptions取值为{block: "start", inline: "nearest"}。如果为 false,元素的底端将和其所在滚动区的可视区域的底端对齐。即可选参数scrollIntoViewOptions取值为{block: "end", inline: "nearest"}。而可选参数scrollIntoViewOptions是包含以下属性的对象:
- behavior:可选,定义动画过渡效果,auto 或 smooth 之一。默认为 auto。
- block:可选,定义垂直方向的对齐,start、center、end 或 nearest 之一。默认为 start。
- Inline: 可选定义水平方向的对齐,start、center、end 或 nearest 之一。默认为 nearest。
NodeList
NodeList 类数组对象是节点的集合,通常是由属性或方法返回的。Node.childNodes 返回实时集合,意味着如果文档中的节点树发生变化,NodeList 也会随之变化;而document.querySelectorAll返回的是静态 NodeList,意味着随后对文档对象模型的任何改动都不会影响集合的内容。
HTMLCollection
HTMLCollection 接口表示一个包含了元素(元素顺序为文档流中的顺序)的通用集合(与 arguments 相似的类数组 (array-like) 对象),还提供了用来从该集合中选择元素的方法和属性。HTML DOM 中的 HTMLCollection 是即时更新的(live);当其所包含的文档结构发生改变时,它会自动更新。因此,最好是创建副本(例如,使用 Array.from)后再迭代这个数组以添加、移动或删除 DOM 节点。
Element
Element.scrollHeight /Element.scrollWidth只读属性是元素内容高度/宽度的度量,包括由于溢出导致的视图中不可见内容,包括元素的padding、伪元素的高度/宽度但不包括border、margin和水平/垂直滚动条。如果元素不需要垂直/水平滚动条就可以容纳,则Element.scrollHeight / Element.scrollWidth等于Element.clientHeight / Element.clientWidth。该属性将会对值round(四舍五入)取整,如果需要小数值,使用 Element.getBoundingClientRect()。

Element.scrollLeft / Element.scrollTop 属性获取或设置元素内容从其左/上边缘即水平/垂直滚动的像素数,默认是整数,然而在使用显示比例缩放的系统上,scrollLeft/scrollTop可能会是一个小数。如果元素不能滚动(比如:元素没有溢出或有"non-scrollable"属性),那么scrollLeft 的值是 0。如果给scrollLeft / scrollTop设置的值小于 0,那么scrollLeft / scrollTop 的值将变为 0。如果给scrollLeft / scrollTop设置的值大于元素内容最大宽度,那么scrollLeft / scrollTop的值将被设为元素最大宽度。当在根元素(<html>元素)上使用scrollTop时,将返回窗口的scrollY。如果元素的内容排列方向(direction)是rtl (right-to-left) ,那么滚动条会位于最右侧(内容开始处),并且scrollLeft值为 0。此时,当从右到左拖动滚动条时,scrollLeft 会从 0 变为负数。
Element.clientWidth / Element.clientHeight只读属性是元素内部的宽度(以像素为单位),不包括由于溢出导致的视图中不可见内容。对于内联元素以及没有 CSS 样式的元素为 0。该属性包括内边距(padding),但不包括边框(border)、外边距(margin)和垂直/水平滚动条(如果存在)。在根元素(<html> 元素)或怪异模式下的 <body> 元素上使用 clientWidth 时,该属性将返回视口宽度(不包含任何滚动条)。Element.clientWidth = CSS width + CSS padding - 垂直滚动条宽度;Element.clientHeight = CSS height + CSS padding - 水平滚动条高度。该属性将会对值round(四舍五入)取整,如果需要小数值,使用 Element.getBoundingClientRect()。
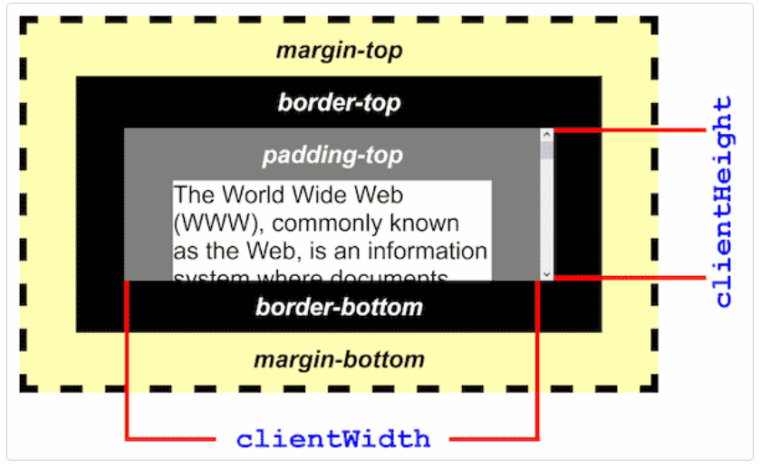
Element.clientLeft / Element.clientTop只读属性表示元素的左/上边框的宽度(以像素为单位),不包括左/上外边距和左/上内边距。如果元素的文本方向是从右向左(RTL, right-to-left),并且由于内容溢出导致左边出现垂直滚动条,则该属性包括滚动条的宽度。
HTMLElement.offsetWidth / HTMLElement.offsetHeight只读属性,返回元素的布局宽度。典型的(各浏览器的 offsetWidth / offsetHeight可能有所不同)offsetWidth / offsetHeight 是测量包含元素的边框 (border)、水平/垂直线上的内边距 (padding)、竖直/水平方向滚动条 (scrollbar)(如果存在的话)、以及 CSS 设置的宽度/高度 (width/height) 的值,但不包含:before 或:after 等伪类元素的宽度/高度。如果元素被隐藏(display:none),则返回0。该属性将会对值round(四舍五入)取整,如果需要小数值,使用 Element.getBoundingClientRect()。
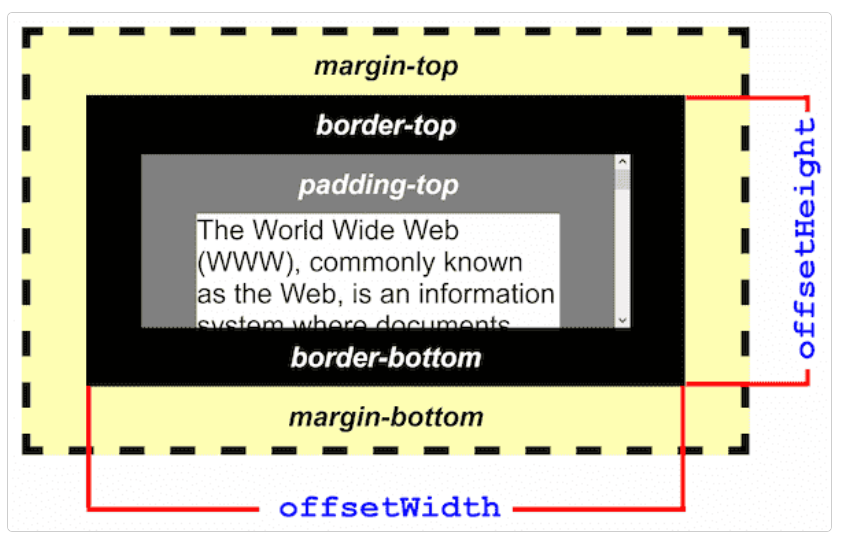
Element.getBoundingClientRect()方法返回一个 DOMRect 对象,是考虑transform后的包含整个元素的最小矩形(包括 padding 和 border-width)。该对象使用以像素为单位的只读属性的 left、top、right、bottom、x、y(IE 浏览器不支持x、y)、width 和 height 描述整个矩形的位置和大小。除了 width 和 height 以外的属性是相对于视图窗口的左上角来计算的。width 和 height 属性是包含了 padding 和 border-width 的,而不仅仅是内容部分的宽度和高度。在标准盒子模型中,这两个属性值分别与元素的 width/height + padding + border-width 相等。而如果是 box-sizing: border-box,两个属性则直接与元素的 width 或 height 相等。
JSON
JSON(JavaScript Object Notation)是一种语法,用来序列化对象、数组、数值、字符串、布尔值和 null 。它基于 JavaScript 语法,但与之不同:JavaScript 不是 JSON,JSON 也不是 JavaScript。
JavaScript 与 JSON 的区别:
- 对象和数组(JSONObject和JSONArray):属性名称必须是双引号的字符串;最后一个属性后不能有逗号。
- 数值(JSONNumber):禁止出现前导零(JSON.stringify 方法自动忽略前导零,而在 JSON.parse 方法中将会抛出 SyntaxError);如果有小数点,则后面至少跟着一位数字。
- 字符串(JSONString):只有有限的一些字符可能会被转义;禁止某些控制字符;Unicode 行分隔符(U+2028)和段分隔符(U+2029)被允许,JavaScript中则不允许; 字符串必须用双引号。
- JSON 仅支持的空白字符:制表符(U+0009),回车(U+000D),换行(U+000A)以及空格(U+0020),这些可以出现在JSONNumber之外。

JSON对象,继承自Object,包含两个方法:
- 用于解析 JSON字符串的 JSON.parse(text[, reviver]):
- text:要被解析成 JavaScript 值的字符串。
- reviver:转换器,解析值本身以及它所包含的所有属性,会按照从最里层的属性开始往外到顶层即解析值本身的顺序分别调用 reviver 函数,在调用过程中,当前属性所属的对象会作为 this 值,当前属性名和属性值会分别作为第一个和第二个参数传入 reviver 中。如果 reviver 返回 undefined,则当前属性会从所属对象中删除,如果返回了其他值,则返回的值会成为当前属性新的属性值。当遍历到最顶层的值(解析值)时,传入 reviver 函数的参数会是空字符串 ""(因为此时已经没有真正的属性)和当前的解析值。当前的 this 值会是 {"": 修改过的解析值}。
- 返回值Object 类型,对应给定 JSON 文本的对象/值。
- 若传入的字符串不符合 JSON 规范,则会抛出 SyntaxError 异常。
- 用于将对象/值转换为 JSON 字符串的JSON.stringify(value[, replacer [, space]]):
- value将要序列化成 一个 JSON 字符串的值。
- replacer :如果该参数是一个函数,则在序列化过程中,被序列化的值的每个属性都会经过该函数的转换和处理;如果该参数是一个数组,则只有包含在这个数组中的属性名才会被序列化到最终的 JSON 字符串中;如果该参数为 null 或者未提供,则对象所有的属性都会被序列化。
- space:指定缩进用的空白字符串,用于美化输出(pretty-print);如果参数是个数字,它代表有多少的空格;上限为 10。该值若小于 1,则意味着没有空格;如果该参数为字符串(当字符串长度超过 10 个字母,取其前 10 个字母),该字符串将被作为空格;如果该参数没有提供(或者为 null),将没有空格。
- 被转换值如果有 toJSON() 方法,将是该方法返回的值被序列化。
- 非数组对象的属性不能保证以特定的顺序出现在序列化后的字符串中。
- 布尔值、数字、字符串的包装对象在序列化过程中会自动转换成对应的原始值。
- undefined、任意的函数以及 symbol 值,在序列化过程中会被忽略(出现在非数组对象的属性值中时)或者被转换成 null(出现在数组中时)。函数、undefined 被单独转换时,会返回undefined,如JSON.stringify(function(){}) or JSON.stringify(undefined).
- 对包含循环引用的对象(对象之间相互引用,形成无限循环)执行此方法,会抛出错误。
- 所有以 symbol 为属性键的属性都会被完全忽略掉,即便 replacer 参数中强制指定包含了它们。
- Date 日期调用了 toJSON() 将其转换为了 string 字符串(同 Date.toISOString()),因此会被当做字符串处理。
- NaN 和 Infinity 格式的数值及 null 都会被当做 null。
- 其他类型的对象,包括 Map/Set/WeakMap/WeakSet,仅会序列化可枚举的属性。
- 当在循环引用时会抛出异常TypeError。
- 当尝试去转换 BigInt 类型的值会抛出TypeError(BigInt 值不能 JSON 序列化)。
- JSON 文件的文件类型是 .json。
- JSON 文本的 MIME 类型是 application/json。
Javascript 动画
setInterval(callback, delay) 特定时间间隔进行变化,每秒24帧以上的变化即看起来流畅。传统动画是通过 setTimeout 和 setInterval 进行实现,缺点是动画的时间间隔不好确定而且会受到UI线程忙碌的阻塞。
window.requestAnimationFrame(callback) 告诉浏览器希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画,因此,若需要在连续帧中不断更新动画,那么回调函数自身必须再次调用 window.requestAnimationFrame(callback)。该回调函数会被传入DOMHighResTimeStamp参数,该参数与performance.now()的返回值相同,它表示requestAnimationFrame() 开始去执行回调函数的时刻,是从页面加载开始经过的毫秒数。返回值是非零的long整数,可以传入window.cancelAnimationFrame() 以取消回调函数。该函数的回调将与其他 requestAnimationFrame 回调组合起来,在每帧只会有一次重绘或回流。在连续帧中,回调函数执行次数通常是每秒 60 次,但在大多数遵循 W3C 建议的浏览器中,回调函数执行次数通常与浏览器屏幕刷新次数相匹配。而且当requestAnimationFrame() 运行在后台标签页或者隐藏的iframe 里时,会被暂停调用以提升性能和电池寿命。
基于 requestAnimationFrame 的通用动画函数:
/**
* animation 函数接受 3 个描述动画的基本参数:
* timing: 时间函数,传入一个已过去的时间与总时间之比的小数(0 代表开始,1 代表结束),返回动画完成度(0 代表开始,1 代表结束)
* draw: 绘制函数,传入动画完成度(0 代表开始,1 代表结束),并绘制
* duration: 动画总时间
* isInfinite: 是否无限动画
* delay: 动画提前执行,取值负数或0,如果为负数说明动画已经执行了多少
*/
function animation({
timing,
draw,
duration,
isInfinite = false,
delay = 0,
}: {
timing: (pass: number) => number;
draw: (progress: number) => void;
duration: number;
isInfinite: boolean;
delay: number;
}) {
let start = performance.now();
window.requestAnimationFrame(function animate(time) {
// 动画提前时间
const advanceTime = delay < 0 ? -delay * duration : 0;
let timeFraction;
if (isInfinite) {
// timeFraction 从 0 增加到 1
timeFraction = ((time + advanceTime - start) % duration) / duration;
} else {
// timeFraction 从 0 增加到 1,可能大于1
timeFraction = (time + advanceTime - start) / duration;
};
// 有限动画且已过去时间超过总时间
if (!isInfinite && timeFraction > 1) {
timeFraction = 1;
};
// 计算当前动画状态
const progress = timing(timeFraction);
draw(progress); // 绘制
if (isInfinite) {
// 无限动画
window.requestAnimationFrame(animate);
} else if (timeFraction < 1) {
// 有限动画
window.requestAnimationFrame(animate);
};
});
}
export default animation;Flip 动画,是 First、Last、Invert和 Play四个步骤的缩写:
- First,记录元素的初始状态;
- Last,记录该元素发生变化后的结束状态;
- Invert,将元素变到初始状态;
- Play,使用动画还原元素到结束状态。
书写基本规范
不要在同一行声明多个变量、
使用 ===/!==来比较true/false或者数值、
使用字面量代替new Array()、
Switch必须使用default分支、
for循环和if语句必须使用花括号、
for.. in 循环中的变量应该使用let/const等关键字等限定作用域,从而避免作用域污染、
避免使用全局函数。
控制语句
JavaScript 没有 goto 语句。label标记语句可以且只能和 break 或 continue 语句一起使用,来指示程序是否中断循环或继续执行。标记就是在一条语句前面加个可以引用的标识符(identifier)。

label是任何不属于保留关键字的 JavaScript 标识符。在严格模式中,你不能使用“let”作为label名称。它会抛出一个 SyntaxError(因为 let 是一个保留的标识符)。 statement是JavaScript 语句。break 可用于任何标记语句,而 continue 可用于循环标记语句。在严格模式中,标记函数声明会抛出 SyntaxError(SyntaxError: functions cannot be labelled)。无论是否处于严格模式下,生成器函数都不能被标记。 使用标记的循环或语句块非常罕见。通常情况下,可以使用函数调用而不是(基于标记的)循环跳转。